Estimating education and skill requirements from job ads
Keywords: education, skill, job, NLP, machine learning, transfer learning
Project coordinator: Prof. Conny Wunsch
CeDA collaborator: Rodrigo C. G. Pena
Repository: nlp-job-ads
Models: gbert-base-ft-edu-redux, gbert-large-ft-edu-redux
Project objectives
- To extract formal education required by jobs from original job ad text using modern Natural Language Processing (NLP) tools.
- To assess and improve upon the skills extracted from a commercial job listings API platform.
- To adjust education and skill requirements to the Swiss context.
This CeDA collaboration is related to the Job Analysis To Track Skill Demand Evolution (JADE):
The digital transformation causes substantial shifts in the tasks associated with specific jobs and the skills and competencies demanded by employers. The extent of possible disparities this will create on the labour market will crucially depend on how labour supply responds to these developments. Moreover, digitalisation disrupts entire management systems, creating both new opportunities, and challenges for the formation and design of employment relationships. JADE is part of a project funded by the Swiss National Science Foundation within the National Research Program “Digital Transformation” (NRP77). In this project, we investigate how the digital transformation changes employment relationships and the matching of labour supply and demand in Switzerland. In JADE, we use large and regularly updated representative data on job vacancies posted in Switzerland to uncover the skills and competencies demanded by employers and analyse how they change over time. This information will serve as input for studying how firms and workers respond to these changes.
Approaches
We predict the education requirements from the job description using a "fine-tunning" approach. Neural networks trained on a variety of NLP tasks are made available to the public every day on hubs such as huggingface.co. Even though these models might not directly apply to the task we are interested in, they nonetheless "know" a lot about the language they we trained on. We may thus use such a pre-trained model as a starting point and adapt (fine-tune) it to the task we care about by presenting it to a newly-curated dataset.
In partnership with Prof. Conny Wunsch's group, we have annotated the education requirements of thousands of job ads and used these to fine-tune state-of-the-art NLP models to be able to reliably predict education requirements on the go. The development is open sourced, available at gitlab.com/ceda-unibas/nlp-job-ads.
Usage example
You may use the fine-tuned models in your local machine by following the installation instructions in the code repository. Alternatively, the models (one of "base" size and one of "large") were uploaded to the huggingface hub, so you may try them via the hub's web interface. For example, here are the scores that the "large" model predicts for an excerpt of a job ad looking for a specialist in internal medicine. Remark: the output of the hub's web interface was modified for better readability.
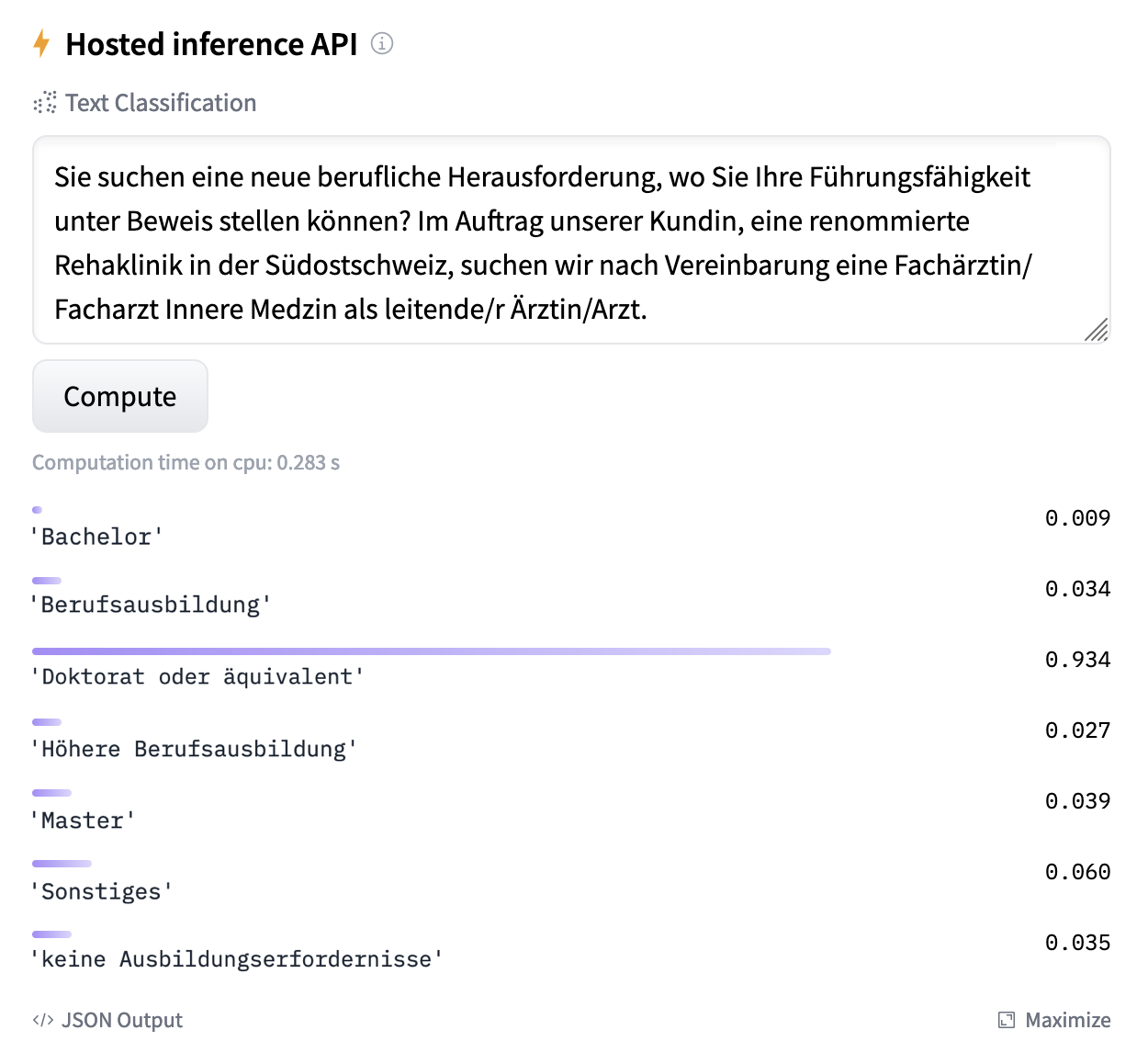
Figure 1. Prediction scores of the "large" fine-tuned model for an internal medicine specialist job ad. Higher scores indicate the model's preference for the corresponding label. The label 'Doktorat oder äquivalent' is seen as the most likely requirement for the sample text.¶